
IA 101 – Où les premiers pas de l’Intelligence Artificielle
A l’heure où l’IA envahit les écrans et les conversations, nourrit de nouvelles angoisses sociétales et redéfinit la place de l’Homme dans les processus de création et de production, nous, professionnels du logiciel devons faire œuvre de pédagogie et de mise en perspective de cette Informatique Avancée.


“Saurons nous expliquer à notre petite cousine et à notre grand-mère
ce que sont l’Intelligence Artificielle et ses enjeux ?”
Et pour cela la compréhension des fondamentaux, en particulier celle des algorithmes appartenant à la grande famille IA, constitue notre valeur ajoutée et notre contribution aux débats.
- Quelles sont les classes de problèmes couvertes par ces algorithmes ?
- Quels sont les domaines d’usage et de validité de ces différents algorithmes ?
- Pourquoi ces algorithmes, dont certains datent des années 40, connaissent-ils actuellement un regain d’intérêt ?
Par exemple, sur votre table de cuisine, il y a des petits pois et des billes de plomb. Comment les séparer ?
Les succès de l’IA connexionniste
La famille IA se structure en deux grandes branches – parfois complémentaires mais souvent rivales :
- L’IA symbolique (les neats) repose sur le raisonnement formel et la logique (moteur de règles, programmation par contraintes, systèmes experts…) qui garantissent une approche déterministe et des résultats explicables,
- L’IA connexionniste (les scruffies) (réseaux neuronaux, machine learning, deep learning…) utilise des approches statistiques, voire probabilistes, qui nécessitent de gros volumes de données d’apprentissage et ne permettent pas ‘d’expliquer’ les résultats obtenus.
{kind=link}

Les récents progrès de l’IA sont liés à la branche connexionniste, à l’existence de gros volumes de données (issues de l’IoT ou des réseaux sociaux) et à la puissance de calcul disponible dans le Cloud.
Les méthodes de l’IA connexionniste sont de nature probabilistes et les résultats produits sont non formels et exprimés sous la forme d’un pourcentage de véracité (« il est probable à 80% que cette pièce sera en panne dans 3 mois »). On va pouvoir prédire mais sans forcément comprendre !
| Pour aller plus loin sur les distinctions IA symbolique / IA connexionniste : – Olivier Ezratty : http://www.oezratty.net/wordpress/2018/que-devient-ia-symbolique/ – Marvin Minsky : https://www.aaai.org/ojs/index.php/aimagazine/article/view/894/812 |
Les grands domaines d’applications de ces algorithmes IA connexionnistes sont :
| La classification d’éléments. | Identifier un spam, une tumeur. |
| La prédiction d’événements. | Anticiper une prévision de panne. |
| La découverte de modèles et de relations cachées. | Optimiser l’utilisation de ressources. |
| La détection d’anomalies de comportement. | Détecter une tentative de fraude. |
Premiers éléments d’algorithmie
Les variables prédictives : à partir desquelles on espère faire une prédiction, représentées par un vecteur X = {x1… xp}. Exemple x1= âge du client, x2=son domicile, x3= son niveau étude, ….
La variable cible : dont on souhaite prédire la valeur pour des éléments non encore observés. Représentée par Y qui peut-être une valeur quantitative (ie numérique) ou qualitative (ie un nom de catégorie, ou 0 ou 1). Exemple Y : probabilité de rembourser un crédit.
- Pour une variable cible quantitative on utilisera des modèles dits de ‘régression’.
- Pour une variable cible qualitative on utilisera des modèles dits de ‘classification’.
La fonction de prédiction :
La valeur observée Y dépend d’une fonction entièrement déterminée par les variables prédictives X et d’un bruit aléatoire : Y = FonctionDeterministe(X) + BruitAleatoire(X)
Cette FonctionDeterministe() et ce BruitAleatoire() resteront toujours inconnus. Ce que l’on cherche c’est une approximation – suffisamment bonne – de cette FonctionDeterministe() par une FonctionPrédiction(X) construite à partir des données observées. La fonction de prédiction peut être linéaire (exemple la régression linéaire f(x) = a1.x1 + … + an.xn) ou non linéaire (exemple les machines à vecteurs de support).
Il s’agit d’une approche résolument pragmatique et non académique.
| Le Machine Learning (ML) permet d’automatiser la construction de la FonctionPrédiction() à partir d’un ensemble de données d’apprentissage. La construction de la FonctionPrédiction() constitue la phase d’apprentissage du modèle. |
Les stratégies d’apprentissage
Dans le Machine Learning (ML) on distinguera différentes stratégies d’apprentissage :
- Un apprentissage supervisé avec des données et leurs résultats associés.
- Un apprentissage semi-supervisé avec des données mais sans tous les résultats associés.
- Un apprentissage non supervisé avec des données mais sans aucun résultat associé.
- Un apprentissage par renforcement de capacités avec les règles mais sans les données.
|
Pour apprendre à un enfant à reconnaître une girafe il suffit de 4 photos. Pour entraîner une IA il faut des centaines de milliers de photos. Il faut disposer d’un gros volume des données d’apprentissage ! |
Pour chacune de ces stratégies d’apprentissage, on dispose de plusieurs algorithmes pour construire les fonctions de prédiction correspondantes.
| Apprentissage supervisé et semi-supervisé |
… |
| Apprentissage non supervisé |
… |
| Apprentissage par renforcement de capacités |
… |
Un algorithme possède son domaine d’utilisation (veut-on Prédire / Classifier / Identifier / Détecter), ses caractéristiques d’apprentissage (rapide, lent, avec plus ou moins de données d’apprentissage…) et ses performances (temps, mémoire, précision…).
|
« Quand on n’a qu’un marteau, tous les problèmes deviennent des clous… » Abraham Maslow -> Pratiquer l’IA, c’est donc disposer d’une boite à outils d’algorithmes variés ! |
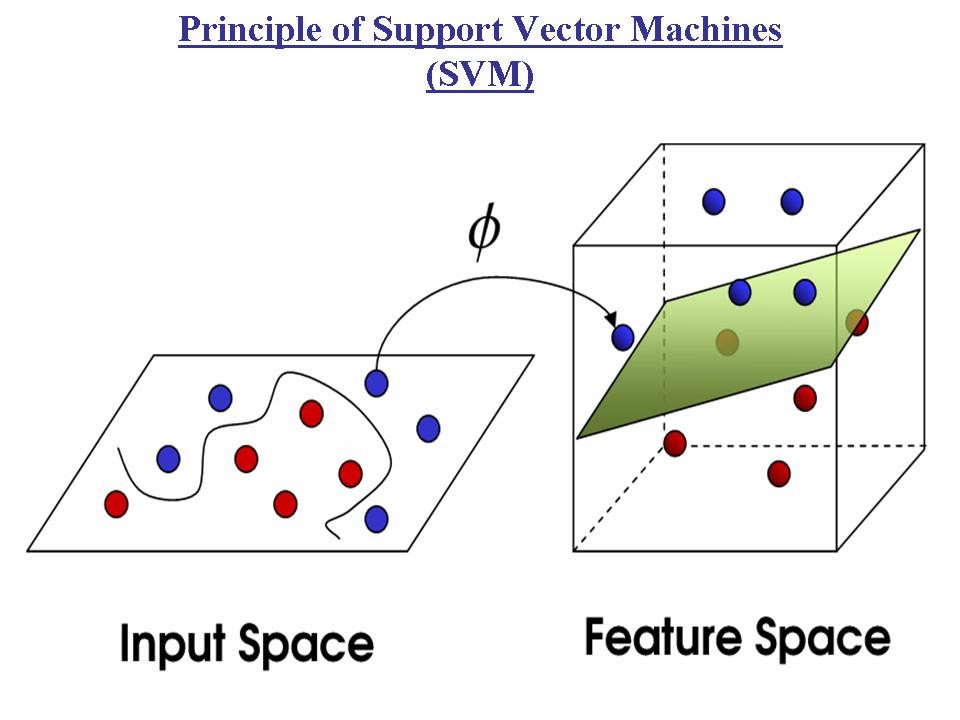
Exemple d’utilisation du Support Vector Machine :
SVM nous suggère de changer de dimension pour trouver alors dans la nouvelle dimension un facteur discriminant qui n’est pas visible dans la dimension initiale. De la table de cuisine (2D) mettre petits pois et billes de plomb dans une casserole d’eau (3D). -> La gravité sera le facteur discriminant. |
 |
Les grandes étapes d’un projet IA – ML
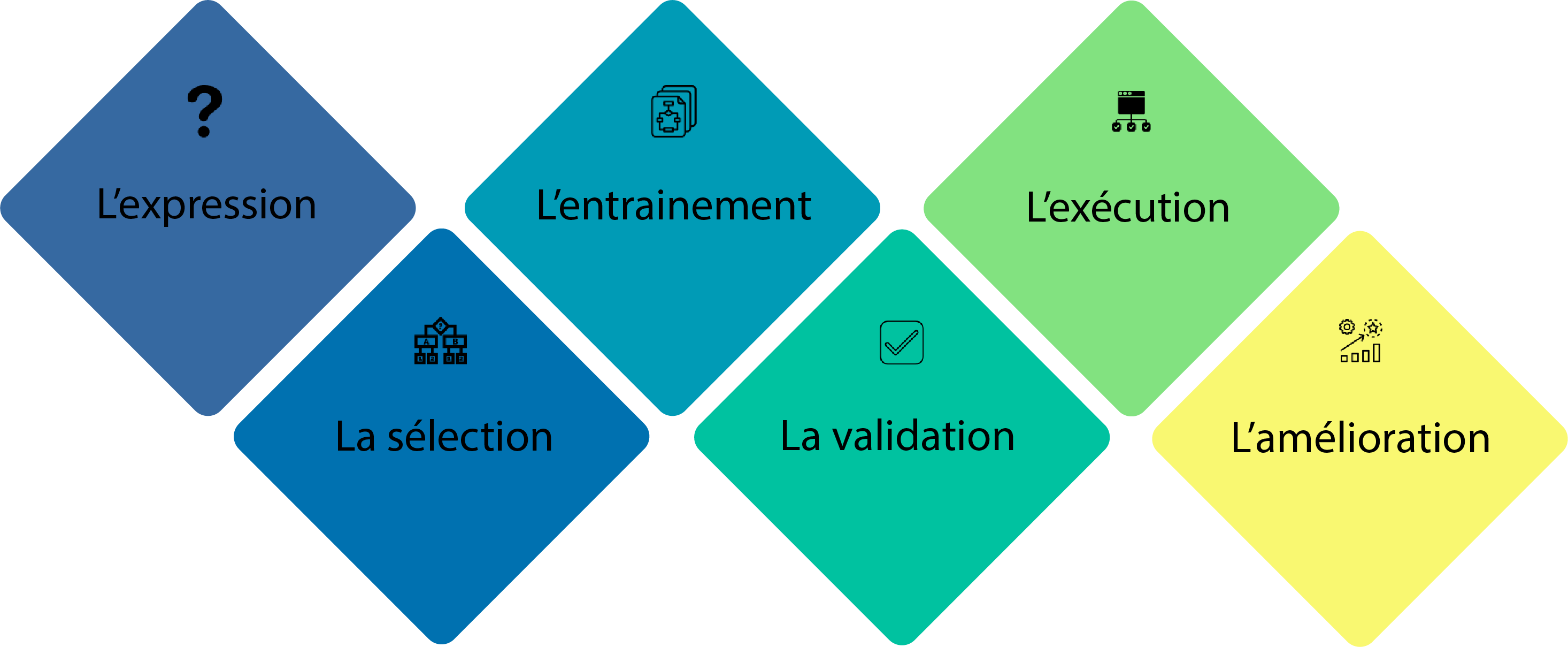
- L’expression du besoin métier avec une question précise.
- La sélection d’un ou de plusieurs algorithmes IA (tous les problèmes ne sont pas des clous).
- L’entrainement de l’algorithme à partir des données d’apprentissage et la construction automatique de la fonction de prédiction.
- La validation de la fonction de prédiction sur des données de tests.
- L’exécution de la fonction de prédiction sur les nouvelles données.
- L’amélioration de l’algorithme avec les nouvelles données.
A suivre…

Directeur associé d’Apitech depuis sa création, Patrick a toujours eu à cœur la recherche et le développement de solutions numériques placées au centre des usages et des métiers. L’intelligence Artificielle est un de ses sujets favoris, mais également la blockchain, les plateformes de services…